
Nonnegative Matrix Factorization Python Tutorial
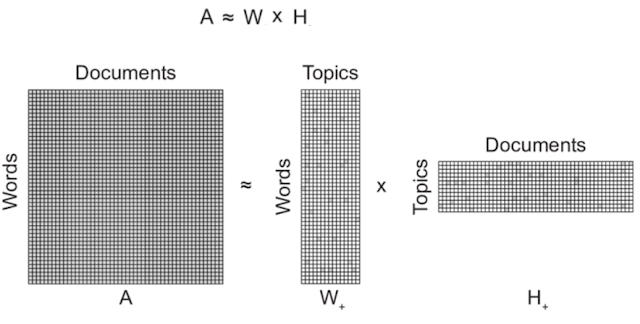
A nonnegative matrix is a matrix whose elements are all nonnegative numbers. Nonnegative matrix factorization (NMF) is a mathematical technique used to factorize nonnegative matrices into two nonnegative matrices of smaller dimensions.
In other words, given a nonnegative matrix A, NMF seeks to find two nonnegative matrices W and H such that A = WH, where W and H are of smaller dimensions than A. This is often useful in data analysis and machine learning, where NMF can be used for tasks such as clustering, feature extraction, and pattern recognition.
One of the key features of NMF is that it enforces sparsity in the factorization, which means that the resulting matrices W and H will often have many elements equal to zero. This can be useful for reducing the dimensionality of a dataset, as well as for identifying important features or patterns in the data.
NMF has been applied in various fields such as image processing, text mining, and bioinformatics, among others.
Nonnegative matrix factorization(NMF) Python code with explanation:
Here's a detailed tutorial on Nonnegative Matrix Factorization (NMF) in Python using the scikit-learn library, with an example:
First, let's install scikit-learn by running the following command in the command prompt or terminal:
Next, we can load our data into a numpy array. For this example, we will use the classic Iris dataset:
Now, we can import NMF from scikit-learn and instantiate the model:
Here, we are specifying that we want to factorize our data into three components using a random initialization with a random seed of 0.
Next, we can fit the model to our data and transform the data into the lower-dimensional representation:
Here, W contains the transformed data and H contains the factorization components.
We can visualize the factorization components using a heatmap:
This will give us a heatmap of the factorization components, where the rows correspond to the components and the columns correspond to the features in the original data.
We can also visualize the transformed data using a scatter plot:
This will give us a scatter plot of the transformed data, where the x-axis corresponds to the first component and the y-axis corresponds to the second component. The color of each point corresponds to the target class of the corresponding iris.
Finally, we can reconstruct our data using the factorization components:
This will give us the reconstructed data using the factorization components.
Overall, this is a basic example of how to use NMF in Python using scikit-learn. There are many additional parameters and options that can be used with NMF, so it's important to consult the scikit-learn documentation for more advanced usage.
So in Python, NMF can be implemented using the scikit-learn library, which provides a simple and intuitive interface for factorizing data. By specifying the number of components and an initialization method, we can fit the model to our data and transform it into a lower-dimensional representation.
No comments: